[CS - OS] 01. 컴퓨터 시스템 개요
[CS - OS] OS.01 Outline Of CS
해당 깃허브의 내용을 참고해서 작성했습니다.
Goal
- 컴퓨터 시스템의 기본 요소와 관계 이해
- 인터럽트 개념과 처리기의 인터럽트 사용 이유에 대한 이해
- 전형적인 컴퓨터 메모리 계층 구조 이해
- 멀티 프로세서의 기본 특성과 멀티 코어의 구조 이해
컴퓨터 구성 요소
- 처리기(Central Processing Unit, CPU): 데이터 연산, 논리 연산(ALU), 제어(Control Unit), 레지스터(Register)
- 주 기억 장치(Main Memory): 메모리 내의 개별적인 저장 공간 (휘발성)
- 저장장치(Storage Device): 디스크, CD-ROM, 플로피 디스크, Flash Memory(비휘발성)
- 입출력 장치
- 통신 장치: Modem, Ethernet, Bluetooth
컴퓨터 구성 요소 (최상위 수준 관점)
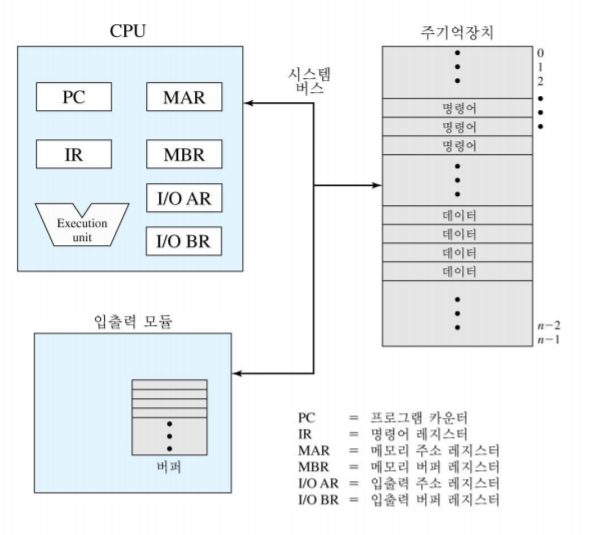
- 메모리 주소 레지스터(Memory Address Register): 다음 번에 읽거나 쓸 주소 명시
- 메모리 버퍼 레지스터(Memory Buffer Register): 메모리에 쓸 데이터를 포함하거나 메모리로부터 수신된 데이터를 포함
- 프로그램 계수기(Program Counter): 다음 실행될 명령어의 주소(실행할 기계어 코드 위치)를 저장
- 명령어 레지스터(Instruction Register): 최근 반입된 명령어 포함(실행 중일 명령어)
- 누산기(AC): 연산 결과를 임시로 저장
- 프로그램 상태 워드(Program Status Word): 인터럽트 가능화/불능화
명령어 실행 2단계
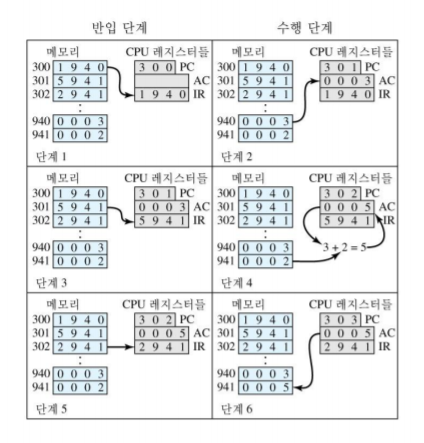
- 반입(Fetch): 처리기가 메모리로부터 명령어를 읽음
- 실행(Execute): 처리기가 각 명령어 수행
인터럽트
- Blocking I/O의 문제점: 대부분의 I/O 디바이스는 처리기보다 느리다. -> 처리기가 디바이스 작업 완료까지 기다려야 하므로 처리기의 성능 저하 유발
- 디바이스 작업이 완료되면 처리기에게 인터럽트를 걸 수 있도록 허용
- 인터럽트와 프로그램 제어 흐름
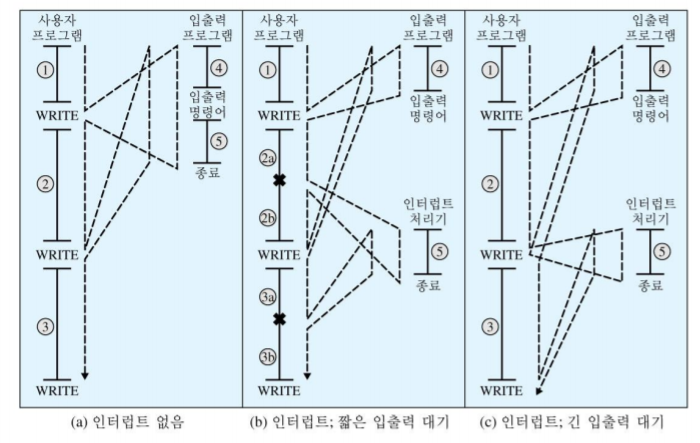
- 인터럽트 처리를 위한 오버헤드가 존재하나, 입출력 연산이 완료되기를 기다리며 낭비하는 시간에 비해 상대적으로 짧음.
메모리 계층 구조
- 접근 시간이 빠르면 비트 당 비용이 높아짐.
- 용량이 크면 비트 당 저장 비용이 낮아지지만, 접근 시간이 길어짐
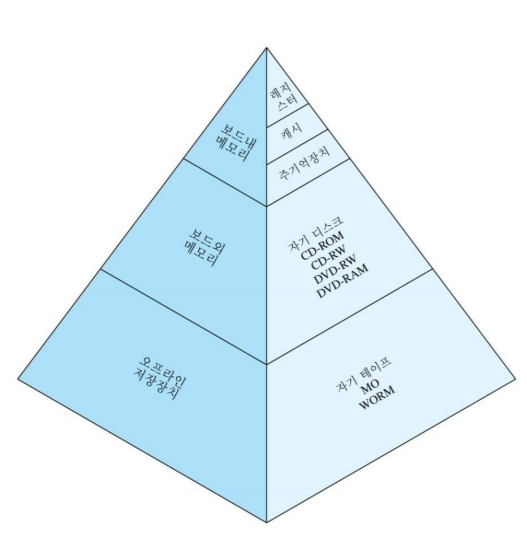
- 계층 구조를 따라 내려갈수록 a. 비트 당 비용이 감소 b. 용량이 증가 c. 접근 속도 감소 d. 처리기가 메모리를 접근하는 횟수 줄어듦.
캐시 메모리
- 운영체제에게 보이지 않고 하드웨어적으로 처리되며, 참조 지역성(Locality of Reference)의 원리를 이용함.
- 캐싱(Cashing): 메모리 계층 구조에 또 다른 레벨을 도입. -> 하나 이상의 레벨에 동시에 저장된 데이터 사이 내용이 일치(consistent)해야 한다!
참조 지역성의 원리
- 프로그램이 실행되는 도중에 처리기에 의해서 접근되는 메모리 영역이 집중화(cluster)되는 경향이 있음.
- 장기적으로 이런 클러스터는 변경될 수 있으나, 짧은 시간에 처리기는 메모리 접근을 고정된 수의 클러스터에 한정하는 경향이 있다.
- 명령어: 반복문, 서브루틴
- 데이터: 테이블, 배열
적중률 (Hit Ratio, H)
- 적중률은 메모리 접근 중 데이터가 빠른 메모리에 존재할 비율로 정의.
- T1은 레벨 1 메모리(캐시 메모리 등) 접근 시간으로 정의
- T1 = 0.1us
- T2는 레벨 2 메모리(메인 메모리 등) 접근 시간으로 정의.
- T2 = 1us
- 메모리 접근 중 95%가 캐시에서 데이터를 찾는 경우(H = 0.95)
- (0.95)(0.1us) + (0.05)(0.1us + 1us) = 0.095 + 0.055(us) = 0.15us
캐시 원칙
- 캐시 크기: 작은 크기의 캐시도 성능에 큰 영향을 미친다.
- 블록 크기
- 캐시와 주 기억장치 사이에 교환하는 데이터 단위.
- 블록 크기가 클수록 적중률이 높아지지만, 너무 커지면 적중률이 더 낮아진다. -> 캐시에서 가져온 데이터를 재사용하기 전에 다른 블록을 가져오기 위해 캐시 내 데이터를 제거해야 하기 때문!
- 매핑 함수: 블록이 캐시의 어느 위치에 저장될 지를 결정.
직접 메모리 접근(Direct Memory Access)
- 기존 인터럽트 구동 I/O는 읽거나 쓸 데이터가 처리기를 통해 이동 -> 처리기 시간 낭비!
- 디바이스 제어기는 처리기의 간섭 없이 주기억장치와 I/O 모듈의 버퍼 사이 데이터 블록을 직접 전송
- 메모리와 I/O 디바이스 사이의 데이터 전송 성능 높임.
- 디바이스 제어기는 “메모리 사이클 훔침(memory cycle steal)” 기법을 이용해 메인 메모리와 I/O 모듈 사이에 데이터를 직접 전송. -> 처리기는 명령어 실행에 지장 받지 않는다!
- DMA 모듈은 데이터 전송을 위해 I/O 제어기를 이용해 I/O 작업이 끝나면 처리기에게 인터럽트를 통해 알림.
- 많은 양의 I/O 연산을 수행하는 시스템(Mainfram, Server 등)의 I/O 성능을 높여준다!
This post is licensed under CC BY 4.0 by the author.